二维数组
多维数组在内存中,本质是特殊的一维数组。
N维数组的元素是N-1维数组。
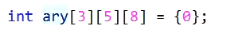
可以理解为
- 针对int[5] [8]的一维数组
- 针对int[8]的二维数组
- 针对int的三维数组
理解成尺子
写一个简单代码,可以看到二维数组其实在内存中也按照地址从小打大顺序排列。
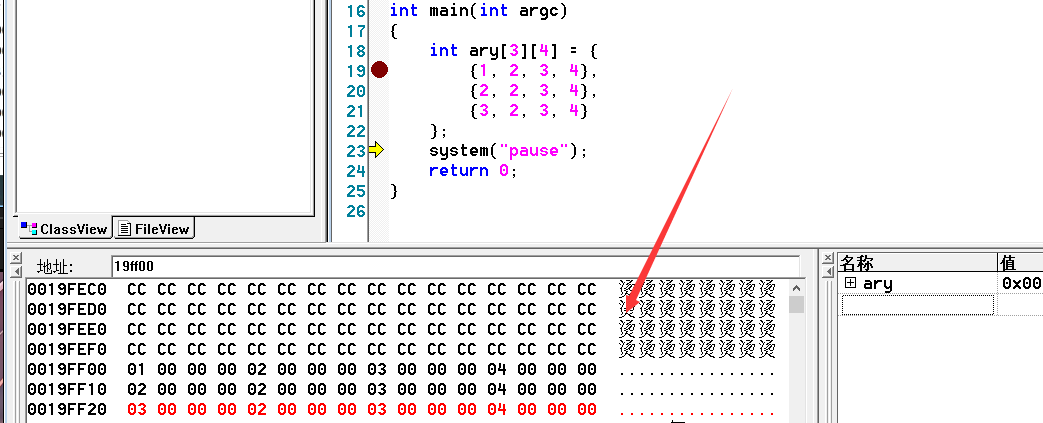
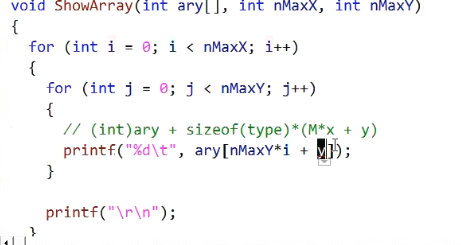
可以得出公式,可以看出两次下标运算(计算机角度)
type ary[N][M]
ary[x][y] address: X,Y是M,Y中的某一个元素
(int)ary+sizeof(type[M])*X // 得出&ary[x] 要算M形数组大小
+sizeof(type)*Y // 得出&ary[x][y]
为什么这里不写[N]?
比如这里要求[2] [2] 就是3
那么就是先ary地址开始,先找到在第几行的第一列,也就是第几行元素的首地址,这里是根据type[4]知道一行四个元素的int,不是简单的int,则到了第三行。
然后下载乃就是一维问题了,直接int 加3位锁定[2] [2]
看看汇编,可以说是完全一样吧。
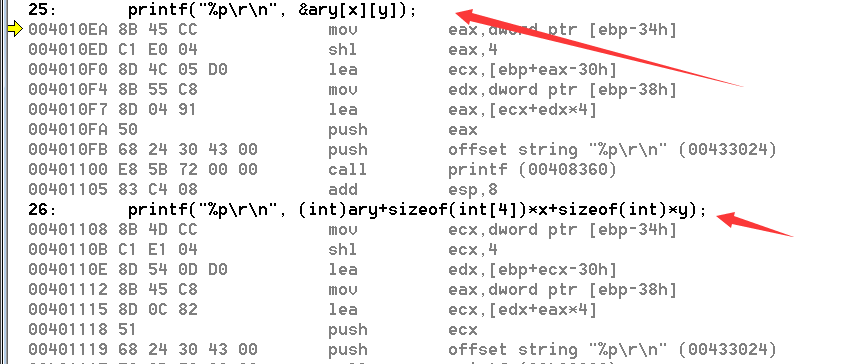
所以可以直接按照公式这么写。直接理解成n次下表运算。
type ary[N][M]
ary[x][y] address: X,Y是M,Y中的某一个元素
(int)ary+sizeof(type[M])*X
+sizeof(type)*Y]
仍然可以进行推导
(int)ary+sizeof(type[M])*X +sizeof(type)*Y
等价于
(int)ary+sizeof(type)*X*M+sizeof(type)*Y
(int)ary+sizeof(type)*(M*X+Y)
前面那个(int)ary+sizeof(type)*
完全等价int[0][?]
再加上(M*X+Y)
变成int[0][M*X+Y]
效果相同,但实际上的汇编不同 下式代码量更少,优化多见。
使用场合也更多,例如 函数的复用性 适用性
折半查找
传统教科书写法,不断更新L和R,两个判断边界。
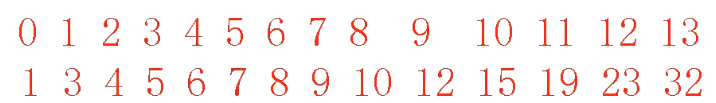

如果L>R break no find
很标准,但速度不够快
- 按照比例, 可以*一个数 然后/10(避免浮点运算,消耗大) 进行查找
- 边界改变,配合顺序查找
算法代价 考虑最坏情况
-
常量阶 算法数量的长短不随n而改变。
比如算递增和的时候,写等差数列就是常量阶,直线
-
线性阶
算递增和的时候,写循环递增 斜线
-
指数阶
斐波那契数列,递归,求阶乘,随大数增长效率越来越低 曲线如x^2。我们优化尽量让他的曲线平稳一点,增长慢一点
-
对数阶
字符数组与字符
字符数组本质上还是数组
Pascal风格,带length

C风格

两者互有优劣,
pascal说用多少就用多少 但是查找十分方便
C风格 说用完就结束 但是难以顺序查找
微软风格

在IDA里面可以看到一些
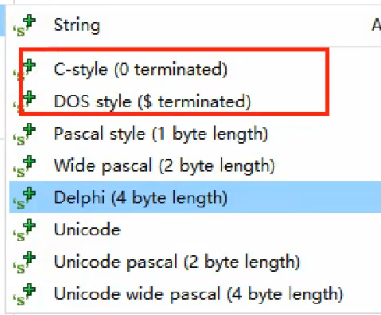
装逼写法,不推崇

strcmp
实际上是两边取字符然后减ascii,如果差不为0,则直接返回差,正数则一大于二,负数则一小于二正常情况下都要到‘\0’,会进行‘\0’减‘\0’