Ollvm三种混淆之BCF,对抗思路以及魔改思路
ok呀 火速赶往ollvm
虚假控制流源码
最先火速赶往战场的是bcf
首先得要有一个概念
虚假控制流是利用不透明谓词,干扰IDA,使它无法确定哪些是虚假的不会进入的基本块,哪些是会进入会执行的基本块。
混淆后
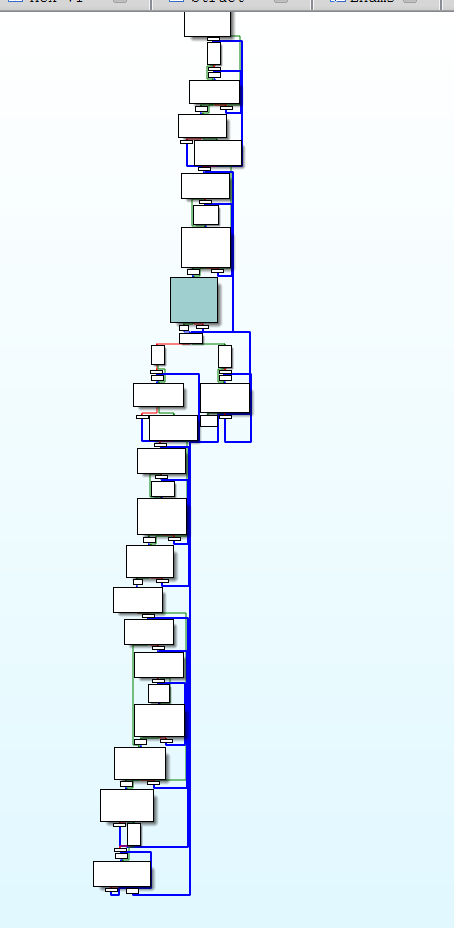
(所谓不透明谓词,是在bss段中定义的变量,被放在代码中,进行一个表达式的判值。而从开发者的角度,我们知道这俩变量是什么值,以至于我们知道这个判断式的值永远为真或者永远为假。但从IDA的角度他不确定这些变量有无改变,以至于不敢随便优化这些判断条件)
那把粒度调小,单个基本块的基本混淆是怎么回事呢
借用这位师傅的博客
http://www.qfrost.com/posts/llvm/llvmbogus%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/#0x07-dof%E5%87%BD%E6%95%B0
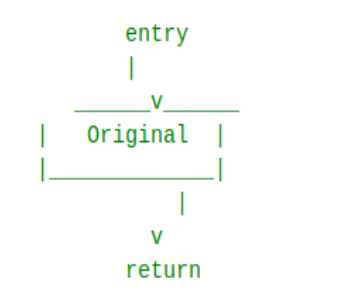
变成
那下面就来看是怎么变成这个样子的
获取参数
这里是获取混淆概率和混淆次数啊
static cl::opt<int>
ObfProbRate("bcf_prob", cl::desc("Choose the probability [%] each basic blocks will be obfuscated by the -bcf pass"), cl::value_desc("probability rate"), cl::init(defaultObfRate), cl::Optional);
static cl::opt<int> the -bcf pass loop o
ObfTimes("bcf_loop", cl::desc("Choose how many time the -bcf pass loop on a function"), cl::value_desc("number of times"), cl::init(defaultObfTime), cl::Optional);
runonfunction
第一个,都要执行的runonfunction啊
virtual bool runOnFunction(Function &F){
// Check if the percentage is correct
if (ObfTimes <= 0) {
errs()<<"BogusControlFlow application number -bcf_loop=x must be x > 0";
return false;
}
// Check if the number of applications is correct
if ( !((ObfProbRate > 0) && (ObfProbRate <= 100)) ) {
errs()<<"BogusControlFlow application basic blocks percentage -bcf_prob=x must be 0 < x <= 100";
return false;
}
// If fla annotations
if(toObfuscate(flag,&F,"bcf")) {
bogus(F);
doF(*F.getParent());
return true;
}
return false;
} // end of runOnFunction()
可以看到显示两个if 这里对参数的合法性做判断,合法之后来到
关键到第三个 先确定参数是不是bcf(就是确定我们是不是要进行bcf混淆)
如果是的话执行两个函数 bogus和doF
bogus
void bogus(Function &F) {
// For statistics and debug
++NumFunction;
int NumBasicBlocks = 0;
bool firstTime = true; // First time we do the loop in this function
bool hasBeenModified = false;
DEBUG_WITH_TYPE("opt", errs() << "bcf: Started on function " << F.getName() << "\n");
DEBUG_WITH_TYPE("opt", errs() << "bcf: Probability rate: "<< ObfProbRate<< "\n");
if(ObfProbRate < 0 || ObfProbRate > 100){
DEBUG_WITH_TYPE("opt", errs() << "bcf: Incorrect value,"
<< " probability rate set to default value: "
<< defaultObfRate <<" \n");
ObfProbRate = defaultObfRate;
}
DEBUG_WITH_TYPE("opt", errs() << "bcf: How many times: "<< ObfTimes<< "\n");
if(ObfTimes <= 0){
DEBUG_WITH_TYPE("opt", errs() << "bcf: Incorrect value,"
<< " must be greater than 1. Set to default: "
<< defaultObfTime <<" \n");
ObfTimes = defaultObfTime;
}
NumTimesOnFunctions = ObfTimes;
int NumObfTimes = ObfTimes;
// Real begining of the pass
// Loop for the number of time we run the pass on the function
do{
DEBUG_WITH_TYPE("cfg", errs() << "bcf: Function " << F.getName()
<<", before the pass:\n");
DEBUG_WITH_TYPE("cfg", F.viewCFG());
// Put all the function's block in a list
std::list<BasicBlock *> basicBlocks;
for (Function::iterator i=F.begin();i!=F.end();++i) {
basicBlocks.push_back(&*i);
}
DEBUG_WITH_TYPE("gen", errs() << "bcf: Iterating on the Function's Basic Blocks\n");
while(!basicBlocks.empty()){
NumBasicBlocks ++;
// Basic Blocks' selection
if((int)llvm::cryptoutils->get_range(100) <= ObfProbRate){
DEBUG_WITH_TYPE("opt", errs() << "bcf: Block "
<< NumBasicBlocks <<" selected. \n");
hasBeenModified = true;
++NumModifiedBasicBlocks;
NumAddedBasicBlocks += 3;
FinalNumBasicBlocks += 3;
// Add bogus flow to the given Basic Block (see description)
BasicBlock *basicBlock = basicBlocks.front();
addBogusFlow(basicBlock, F);
}
else{
DEBUG_WITH_TYPE("opt", errs() << "bcf: Block "
<< NumBasicBlocks <<" not selected.\n");
}
// remove the block from the list
basicBlocks.pop_front();
if(firstTime){ // first time we iterate on this function
++InitNumBasicBlocks;
++FinalNumBasicBlocks;
}
} // end of while(!basicBlocks.empty())
DEBUG_WITH_TYPE("gen", errs() << "bcf: End of function " << F.getName() << "\n");
if(hasBeenModified){ // if the function has been modified
DEBUG_WITH_TYPE("cfg", errs() << "bcf: Function " << F.getName()
<<", after the pass: \n");
DEBUG_WITH_TYPE("cfg", F.viewCFG());
}
else{
DEBUG_WITH_TYPE("cfg", errs() << "bcf: Function's not been modified \n");
}
firstTime = false;
}while(--NumObfTimes > 0);
}
先把整个bogus贴一下吧。
看着吓人,其实重要的部分就两个循环
一个for 把基本块推进basicBlocks
for (Function::iterator i=F.begin();i!=F.end();++i) {
basicBlocks.push_back(&*i);
}
一个while
while(!basicBlocks.empty()){
NumBasicBlocks ++;
// Basic Blocks' selection
if((int)llvm::cryptoutils->get_range(100) <= ObfProbRate){
DEBUG_WITH_TYPE("opt", errs() << "bcf: Block "
<< NumBasicBlocks <<" selected. \n");
hasBeenModified = true;
++NumModifiedBasicBlocks;
NumAddedBasicBlocks += 3;
FinalNumBasicBlocks += 3;
// Add bogus flow to the given Basic Block (see description)
BasicBlock *basicBlock = basicBlocks.front();
addBogusFlow(basicBlock, F);
}
else{
DEBUG_WITH_TYPE("opt", errs() << "bcf: Block "
<< NumBasicBlocks <<" not selected.\n");
}
// remove the block from the list
basicBlocks.pop_front();
if(firstTime){ // first time we iterate on this function
++InitNumBasicBlocks;
++FinalNumBasicBlocks;
}
} // end of while(!basicBlocks.empty())
也是有遍历操作 关键是这个函数addBogusFlow
addBogusFlow 1
这里的比较繁杂,就跟着上面那篇博客的思路做分析好了
BasicBlock::iterator i1 = basicBlock->begin();
if (basicBlock->getFirstNonPHIOrDbgOrLifetime())
i1 = (BasicBlock::iterator)basicBlock->getFirstNonPHIOrDbgOrLifetime();
Twine *var;
var = new Twine("originalBB"); // 新产生的BasicBlock的名称
BasicBlock *originalBB = basicBlock->splitBasicBlock(i1, *var);
// Creating the altered basic block on which the first basicBlock will jump
Twine *var3 = new Twine("alteredBB");
BasicBlock *alteredBB = createAlteredBasicBlock(originalBB, *var3, &F); // 产生了一个新的基本块
两个函数getFirstNonPHIOrDbgOrLifetime函数和splitBasicBlock函数把BasicBlock分成了两部分
第一部分只有PHI Node和一些调试信息
关于PHI Node
所有 LLVM 指令都使用 SSA (Static Single Assignment,静态一次性赋值) 方式表示,即所有变量都只能被赋值一次,这样做主要是便于后期的代码优化。
而PHINode在我的理解是如果一个基本快有多个前驱,而每个前驱都对一个x进行定值了,分别编号为x1,x2,...,xn。那么到达本基本快的时候我究竟该使用哪一个版本的x,这时候PHI函数应运而生,我们可以在本基本块的开头添加PHI函数来进行取值。
createAlteredBasicBlock
这个是一个比较关键的函数
我们会先根据传入的基本块在克隆出一个
ValueToValueMapTy VMap;
BasicBlock * alteredBB = llvm::CloneBasicBlock (basicBlock, VMap, Name, F);
clone出来的基本块有些问题
DEBUG_WITH_TYPE("gen", errs() << "bcf: Operands remapped\n");
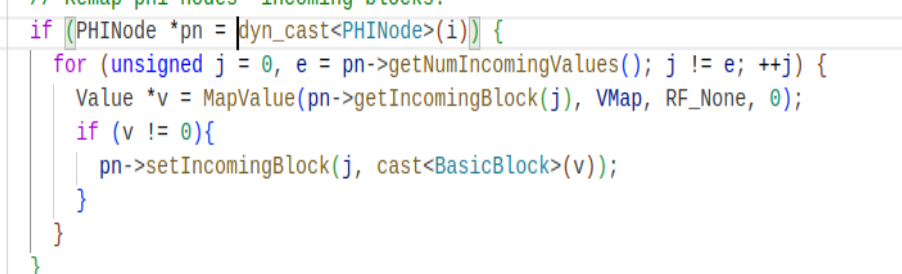
// Remap phi nodes' incoming blocks.
if (PHINode *pn = dyn_cast<PHINode>(i)) {
for (unsigned j = 0, e = pn->getNumIncomingValues(); j != e; ++j) {
Value *v = MapValue(pn->getIncomingBlock(j), VMap, RF_None, 0);
if (v != 0){
pn->setIncomingBlock(j, cast<BasicBlock>(v));
}
}
}
DEBUG_WITH_TYPE("gen", errs() << "bcf: PHINodes remapped\n");
// Remap attached metadata.
SmallVector<std::pair<unsigned, MDNode *>, 4> MDs;
i->getAllMetadata(MDs);
DEBUG_WITH_TYPE("gen", errs() << "bcf: Metadatas remapped\n");
// important for compiling with DWARF, using option -g.
i->setDebugLoc(ji->getDebugLoc());
ji++;
DEBUG_WITH_TYPE("gen", errs() << "bcf: Debug information location setted\n");
} // The instructions' informations are now all correct
上面这些代码其实都是在remap吧,(新变量和新变量之间的映射关系)
同时clone出来的基本块也不会对phinode做任何的处理,所以clone出来的基本块没有前驱块,所以还要对phinode的前驱块进行remap,让他remap到nullptr
这个函数的在之后就是往里面加些垃圾了

ok差不多完成可一个基本块的克隆(垃圾基本块alteredBB)
addBogusFlow 2
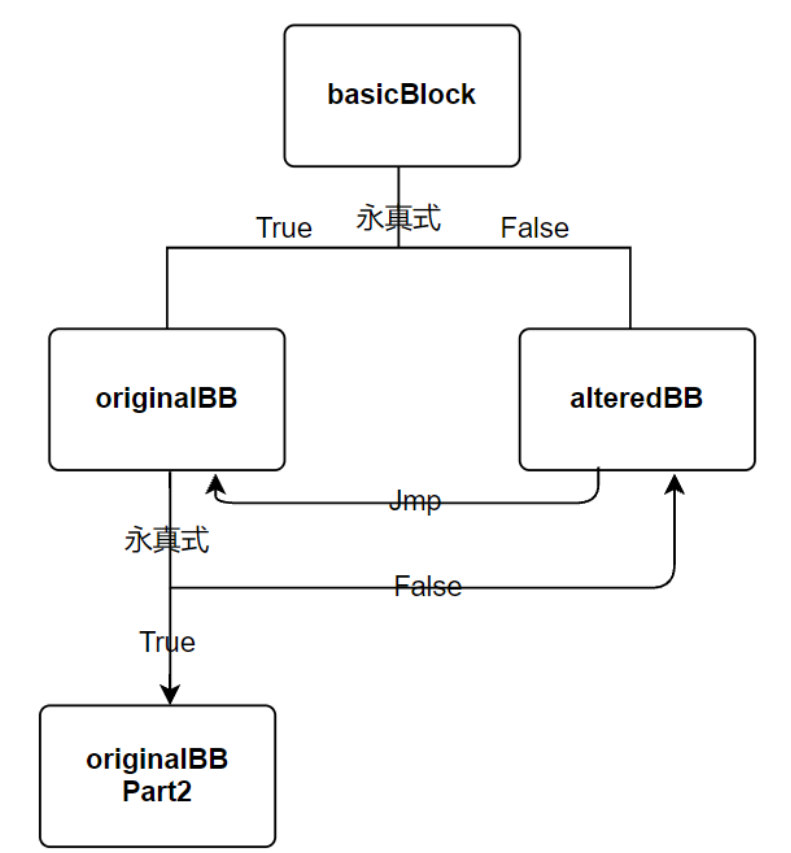
最开始的一个基本块现在变成了三个基本块
一个原始基本块originalBB,和一个克隆出的基本块alteredBB,以及一个只包含PHI Node和Debug信息的基本块basicBlock(就是一开始分离出来的那个)
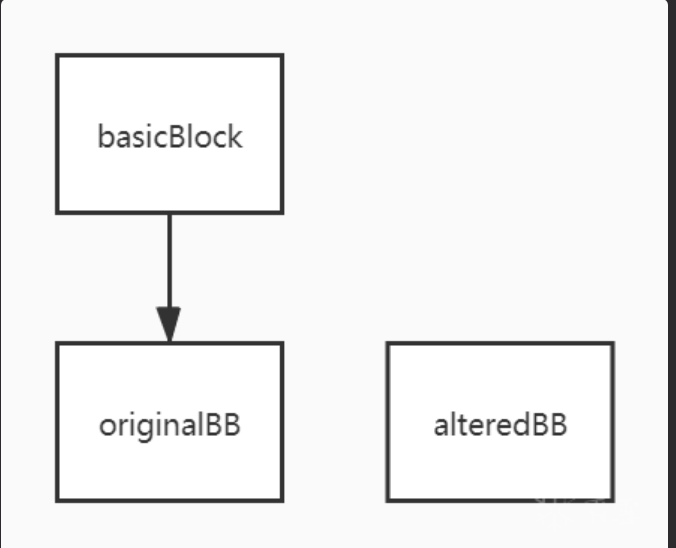
之后会删除basicblock和alteredBB末尾的跳转 建立新的分支指令
alteredBB->getTerminator()->eraseFromParent();
basicBlock->getTerminator()->eraseFromParent();
DEBUG_WITH_TYPE("gen", errs() << "bcf: Terminator removed from the altered"
<<" and first basic blocks\n");
// Preparing a condition..
// For now, the condition is an always true comparaison between 2 float
// This will be complicated after the pass (in doFinalization())
Value * LHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);
Value * RHS = ConstantFP::get(Type::getFloatTy(F.getContext()), 1.0);
DEBUG_WITH_TYPE("gen", errs() << "bcf: Value LHS and RHS created\n");
// The always true condition. End of the first block
Twine * var4 = new Twine("condition");
FCmpInst * condition = new FCmpInst(*basicBlock, FCmpInst::FCMP_TRUE , LHS, RHS, *var4);
DEBUG_WITH_TYPE("gen", errs() << "bcf: Always true condition created\n");
// Jump to the original basic block if the condition is true or
// to the altered block if false.
BranchInst::Create(originalBB, alteredBB, (Value *)condition, basicBlock);
DEBUG_WITH_TYPE("gen",
errs() << "bcf: Terminator instruction in first basic block: ok\n");
// The altered block loop back on the original one.
BranchInst::Create(originalBB, alteredBB);
DEBUG_WITH_TYPE("gen", errs() << "bcf: Terminator instruction in altered block: ok\n");
目前变成如下这个样子
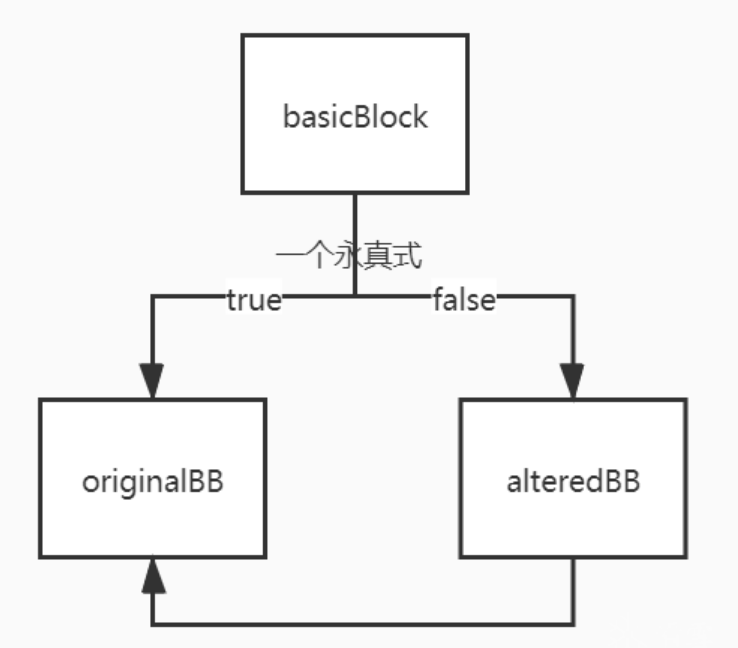
然后
BasicBlock::iterator i = originalBB->end();
// Split at this point (we only want the terminator in the second part)
Twine *var5 = new Twine("originalBBpart2");
BasicBlock *originalBBpart2 = originalBB->splitBasicBlock(--i, *var5); // 截取的originalBB结尾的跳转指令作为一个新的基本块originalBBPart2
originalBB->getTerminator()->eraseFromParent(); // 删除originalBB块末尾跳转
Twine *var6 = new Twine("condition2");
FCmpInst *condition2 =
new FCmpInst(*originalBB, CmpInst::FCMP_TRUE, LHS, RHS, *var6); // 添加永真条件
BranchInst::Create(originalBBpart2, alteredBB, (Value *)condition2, // 添加分支指令,为真时basicBlock->originalBB; 为假时basicBlock->alteredBB
originalBB);
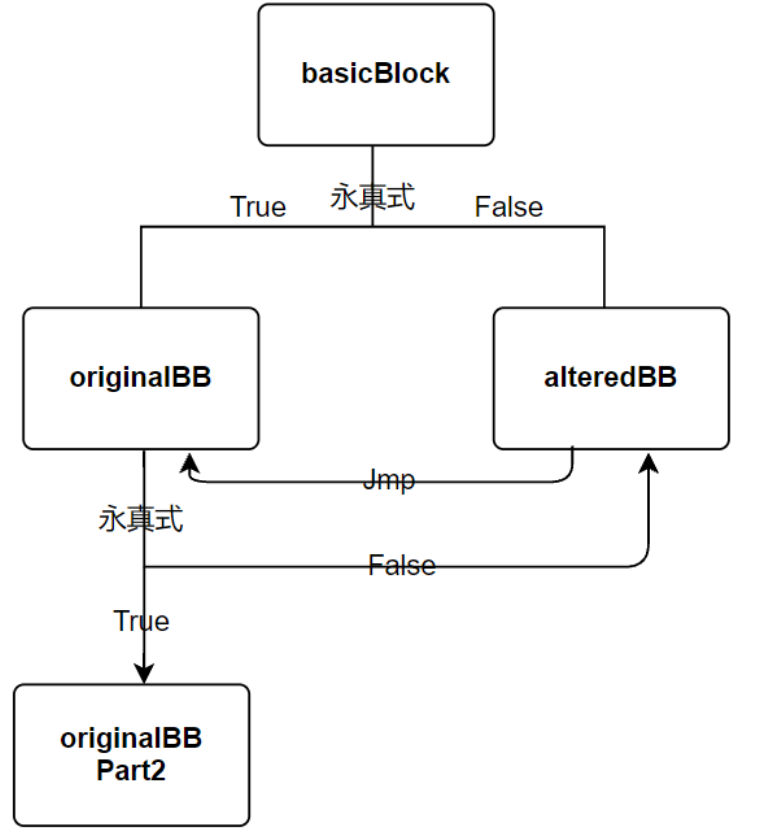
到现在对单一的一个基本块的操作大体完成
doF
doF函数会修改永真式使其变得更加复杂,并会擦除所有基本块、指令和函数的名称
修改永真式
先初始化两个全局变量
// The global values
Twine *varX = new Twine("x"); // 初始化两个全局变量
Twine *varY = new Twine("y");
Value *x1 = ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
Value *y1 = ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false);
GlobalVariable *x =
new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant *)x1, *varX);
GlobalVariable *y =
new GlobalVariable(M, Type::getInt32Ty(M.getContext()), false,
GlobalValue::CommonLinkage, (Constant *)y1, *varY);
然后便利所有函数的所有指令,碰到之前预设的永真式的条件跳转将跳转指令存到toedit向量,将比较指令fcmpinst存到todelete
std::vector<Instruction *> toEdit, toDelete;
BinaryOperator *op, *op1 = NULL;
LoadInst *opX, *opY;
ICmpInst *condition, *condition2;
// Looking for the conditions and branches to transform
for (Module::iterator mi = M.begin(), me = M.end(); mi != me; ++mi) { // 遍历所有Module
for (Function::iterator fi = mi->begin(), fe = mi->end(); fi != fe; // 遍历所有函数
++fi) {
// fi->setName(""); // 删除所有函数名称
Instruction *tbb = fi->getTerminator(); // 获得末尾跳转指令
if (tbb->getOpcode() == Instruction::Br) {
BranchInst *br = (BranchInst *)(tbb);
if (br->isConditional()) {
FCmpInst *cond = (FCmpInst *)br->getCondition();
unsigned opcode = cond->getOpcode();
if (opcode == Instruction::FCmp) {
if (cond->getPredicate() == FCmpInst::FCMP_TRUE) {
DEBUG_WITH_TYPE("gen",
errs() << "bcf: an always true predicate !\n");
toDelete.push_back(cond); // The condition
toEdit.push_back(tbb); // The branch using the condition
}
}
}
}
/* 删除所有基本块和指令名称的代码被注释掉了
for (BasicBlock::iterator bi = fi->begin(), be = fi->end() ; bi != be;
++bi){ bi->setName(""); // setting the basic blocks' names
}
*/
}
}
在遍历toedit列表,添加新的条件跳转,删除旧的条件跳转,变成我的条件跳转
// Replacing all the branches we found
for (std::vector<Instruction *>::iterator i = toEdit.begin();
i != toEdit.end(); ++i) {
// if y < 10 || x*(x-1) % 2 == 0
opX = new LoadInst((Value *)x, "", (*i));
opY = new LoadInst((Value *)y, "", (*i));
op = BinaryOperator::Create(
Instruction::Sub, (Value *)opX,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 1, false), "",
(*i));
op1 =
BinaryOperator::Create(Instruction::Mul, (Value *)opX, op, "", (*i));
op = BinaryOperator::Create(
Instruction::URem, op1,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 2, false), "",
(*i));
condition = new ICmpInst(
(*i), ICmpInst::ICMP_EQ, op,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 0, false));
condition2 = new ICmpInst(
(*i), ICmpInst::ICMP_SLT, opY,
ConstantInt::get(Type::getInt32Ty(M.getContext()), 10, false));
op1 = BinaryOperator::Create(Instruction::Or, (Value *)condition,
(Value *)condition2, "", (*i));
BranchInst::Create(((BranchInst *)*i)->getSuccessor(0),
((BranchInst *)*i)->getSuccessor(1), (Value *)op1,
((BranchInst *)*i)->getParent());
DEBUG_WITH_TYPE("gen", errs() << "bcf: Erase branch instruction:"
<< *((BranchInst *)*i) << "\n");
(*i)->eraseFromParent(); // erase the branch
}
对抗思路
根据网上查阅的blog
大概有四种思路
使用IDApython 手动把x,y的地方(具体变量名看bss段)patch为0,也就是mov xx,x变成mov 0,这样可以进行反编译
https://bbs.kanxue.com/thread-266201.htm#msg_header_h1_6
使用IDApython 手动把jnz的位置patch成jmp (其实这里比较疑惑,观察后我的demo后发现确实适合jnz连用的,但是很多时候本身代码也有jnz啊,这样不会修改别的代码吗)
https://bbs.kanxue.com/thread-266201.htm#msg_header_h1_6
修改IDA 让他识别bss所在segment为只读 这样他就会直接识别出来
使用angr符号执行,其实就是通过符号执行找到所有可以到达的基本块,筛出不可到达的基本块,把这些基本块nop掉,详细可以看这篇博客https://bbs.kanxue.com/thread-266005-1.htm#msg_header_h1_1
使用unidbg模拟执行so,通过tracecode监控,修改调用函数,在调用前挂上监控https://bbs.kanxue.com/thread-267499-1.htm#msg_header_h2_3
魔改思路
别的一些对抗思路我目前还没碰到过
所以主要针对上面四种
1
使用IDApython 手动把x,y的地方(具体变量名看bss段)patch为0,也就是mov xx,x变成mov 0,这样可以进行反编译
这种做法,其实我还没想到什么特别好的思路,因为之前碰到过大一点的so里面其实除了我们不透明谓词所用的变量之外还有别的一些变量,所以在我看如果项目一大,反混淆的重点就从修改xy为0转变成为有哪些xy了,可能是需要配合别的一些魔改思路。当然我接触到的项目很少,只在我随意的思考之中。
其实要说还有一个更加奇思妙想的
还是要保留bss当中的未初始化变量,但让我们参与不透明谓词赋值的这些变量不仅仅用于不透明谓词赋值,不仅仅给他零值,让他参与实际代码的运行,以至于如果我们给他patch为0,正常的函数后续流程会碰到问题
2
使用IDApython 手动把jnz的位置patch成jmp (其实这里比较疑惑,观察后我的demo后发现确实适合jnz连用的,但是很多时候本身代码也有jnz啊,这样不会修改别的代码吗)
https://bbs.kanxue.com/thread-266201.htm#msg_header_h1_6
感觉本身就有问题,如果很要用的话只能根据地址段,分批次进行手动patch,patch掉一个地方,看一下结果,没问题就再下一个。
感觉可行性不是很大。。。
3
使用angr符号执行,其实就是通过符号执行找到所有可以到达的基本块,筛出不可到达的基本块,把这些基本块nop掉
博客里面师傅写的很好,我的思路其实就是在本身的基础上,
让bcf随机的进入一些无意义的虚假控制流
多添加一些很恶心的无限循环,让angr符号爆炸多,增加一些逆向难度
4
使用unidbg模拟执行so,通过tracecode监控,修改调用函数,在调用前挂上监控
我猜测和上面的也差不太大吧,随机的进入一些性能损耗较小的无意义的虚假控制块
上面的思路近期会尝试写一些并给出测试demo,很感谢文中提到的一些博客的作者,给了我很大帮助