省流资源分享
https://github.com/C0raxx/AndroidCompile/tree/main/Android10/Android10SmaliTrace
1 方法的解释执行流程
之前抽取壳看过从java中method的inoke反射调用中的函数调用流程。
Artmethod下的invoke是方法调用的关键,甚至jni最后也会调用到到这个invoke
invoke
函数压栈,这个东西后面可以去得到当前栈帧
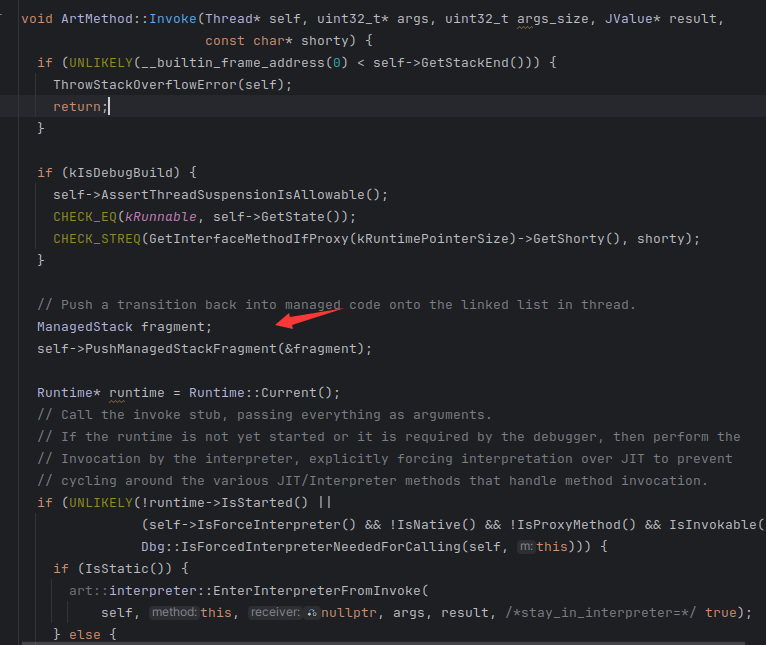
解释模式会走进这个
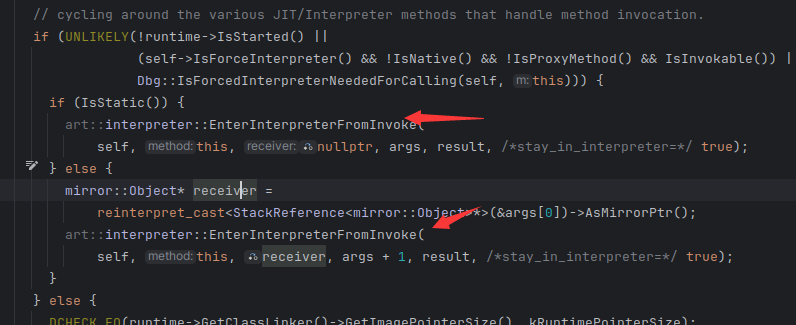
快速模式是俩
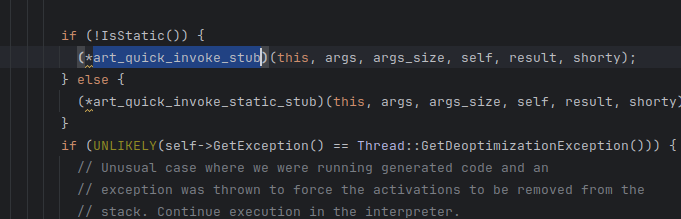
我们进入 EnterInterpreterFromInvoke
这个函数里面负责有些栈的处理,最后会走到这个execute里面去
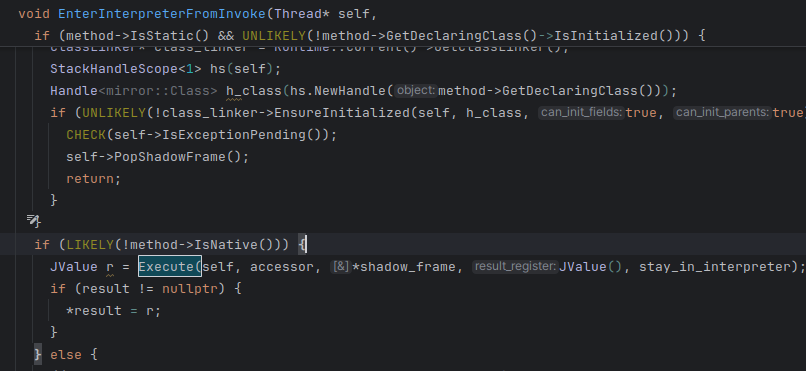
里面重点关注这个,后面需要进行执行代码dump的话,这个需要走到下面 用switch解释执行的模式
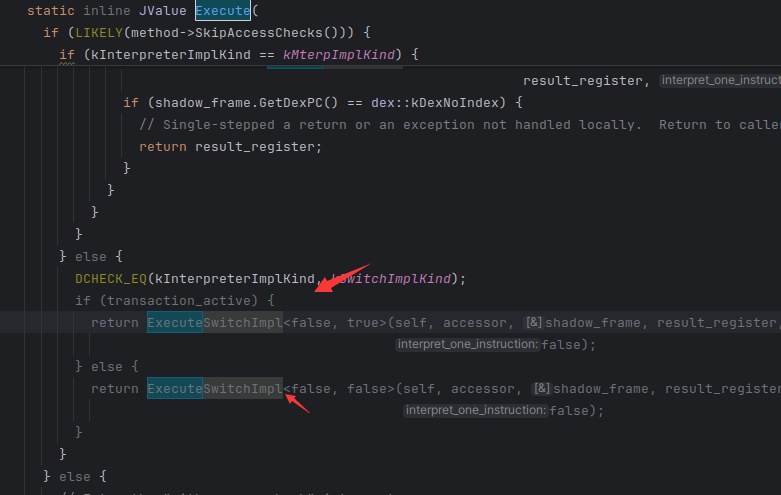
而这个函数的重点是这个
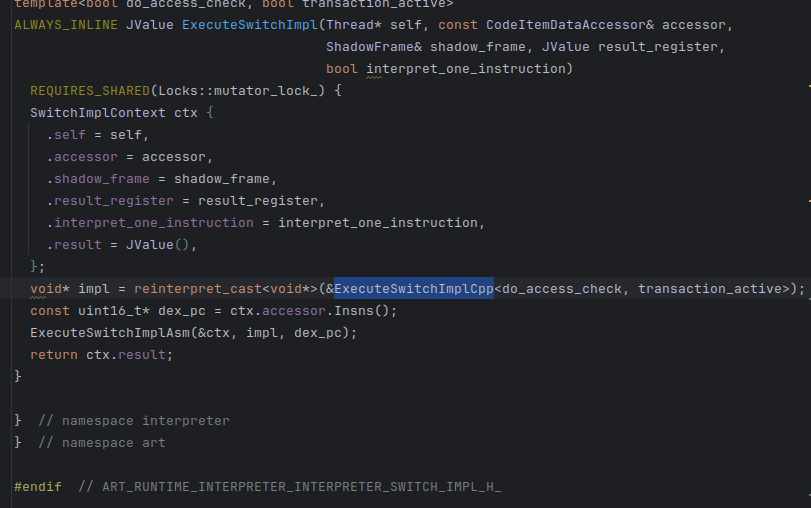
在这里

可以看到并不是很长,但在旧版本,这里代码是很长的,可能到两千行,这里利用宏简化了代码空间,真实编译的时候这里还是很长的。
ATTRIBUTE_NO_SANITIZE_ADDRESS void ExecuteSwitchImplCpp(SwitchImplContext* ctx) {
Thread* self = ctx->self;
const CodeItemDataAccessor& accessor = ctx->accessor;
ShadowFrame& shadow_frame = ctx->shadow_frame;
if (UNLIKELY(!shadow_frame.HasReferenceArray())) {
LOG(FATAL) << "Invalid shadow frame for interpreter use";
ctx->result = JValue();
return;
}
self->VerifyStack();
uint32_t dex_pc = shadow_frame.GetDexPC();
const auto* const instrumentation = Runtime::Current()->GetInstrumentation();
const uint16_t* const insns = accessor.Insns();
const Instruction* inst = Instruction::At(insns + dex_pc);
uint16_t inst_data;
DCHECK(!shadow_frame.GetForceRetryInstruction())
<< "Entered interpreter from invoke without retry instruction being handled!";
bool const interpret_one_instruction = ctx->interpret_one_instruction;
while (true) {
dex_pc = inst->GetDexPc(insns);
shadow_frame.SetDexPC(dex_pc);
TraceExecution(shadow_frame, inst, dex_pc);
inst_data = inst->Fetch16(0);
{
bool exit_loop = false;
InstructionHandler<do_access_check, transaction_active> handler(
ctx, instrumentation, self, shadow_frame, dex_pc, inst, inst_data, exit_loop);
if (!handler.Preamble()) {
if (UNLIKELY(exit_loop)) {
return;
}
if (UNLIKELY(interpret_one_instruction)) {
break;
}
continue;
}
}
switch (inst->Opcode(inst_data)) {
#define OPCODE_CASE(OPCODE, OPCODE_NAME, pname, f, i, a, e, v) \
case OPCODE: { \
bool exit_loop = false; \
InstructionHandler<do_access_check, transaction_active> handler( \
ctx, instrumentation, self, shadow_frame, dex_pc, inst, inst_data, exit_loop); \
handler.OPCODE_NAME(); \
/* TODO: Advance 'inst' here, instead of explicitly in each handler */ \
if (UNLIKELY(exit_loop)) { \
return; \
} \
break; \
}
DEX_INSTRUCTION_LIST(OPCODE_CASE)
#undef OPCODE_CASE
}
if (UNLIKELY(interpret_one_instruction)) {
break;
}
}
// Record where we stopped.
shadow_frame.SetDexPC(inst->GetDexPc(insns));
ctx->result = ctx->result_register;
return;
}
这个函数里面uint32_t dex_pc = shadow_frame.GetDexPC();获得一个一条指令(可能不是很准确)
然后那这个指令去做一个switch case 不同样式的opcode对应不同的case
这句TraceExecution(shadow_frame, inst, dex_pc);也是需要主义的,后面代码追踪rom的定制也需要。
贴一个老版本的这个函数,很长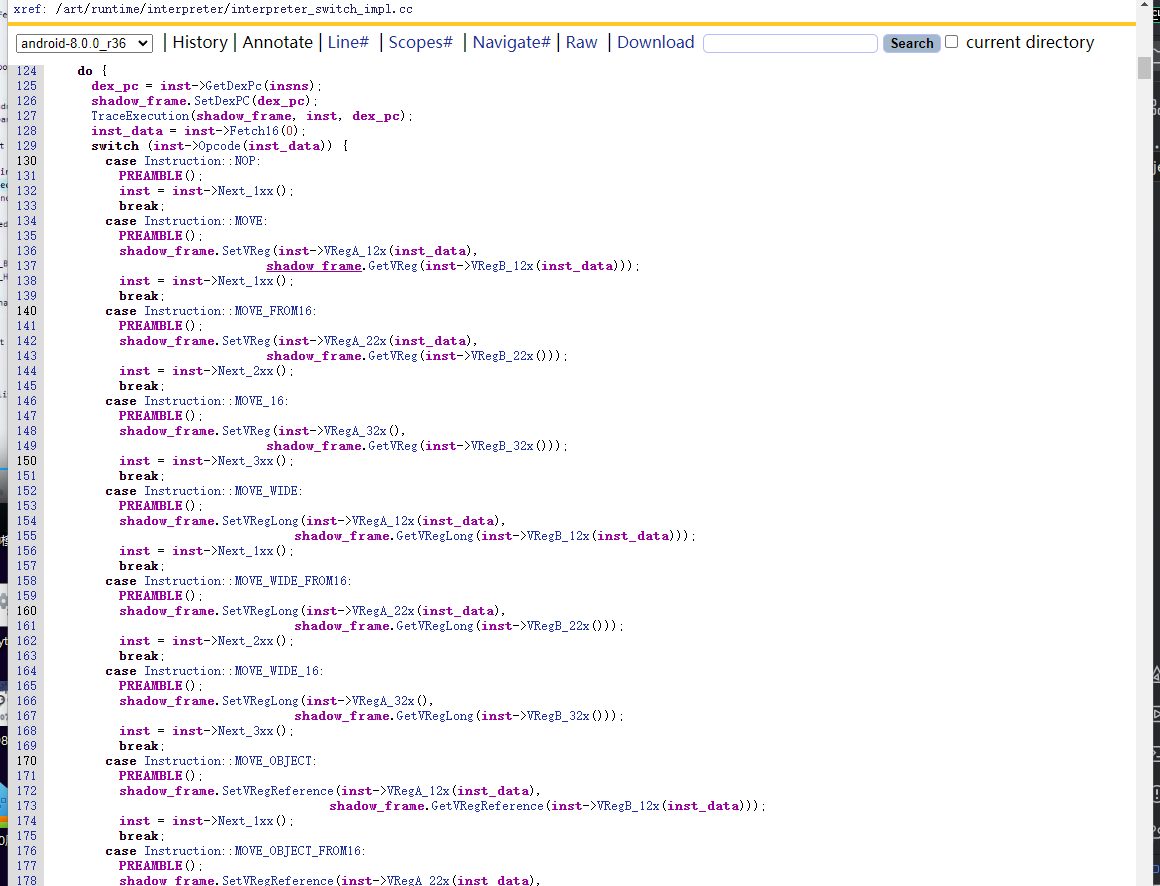
2 invoke指令的执行流程
如果我们有下面这个方法
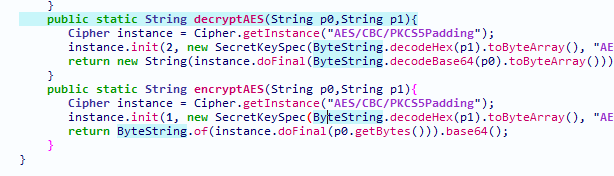
那它的smali是这样的,可以看到涉及到函数调用的基本上都是invoke-xxx的opcode,这在switch里面是写好的
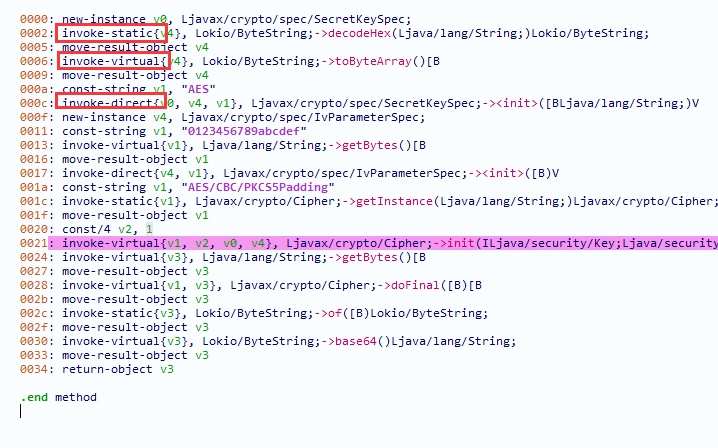
里面都会执行这个doinvoke

这个doinvoke里面有了被调用的函数了,这里其实以及可达一添加代码打印调用关系了,但是无法表示参数,所以可以继续根根看
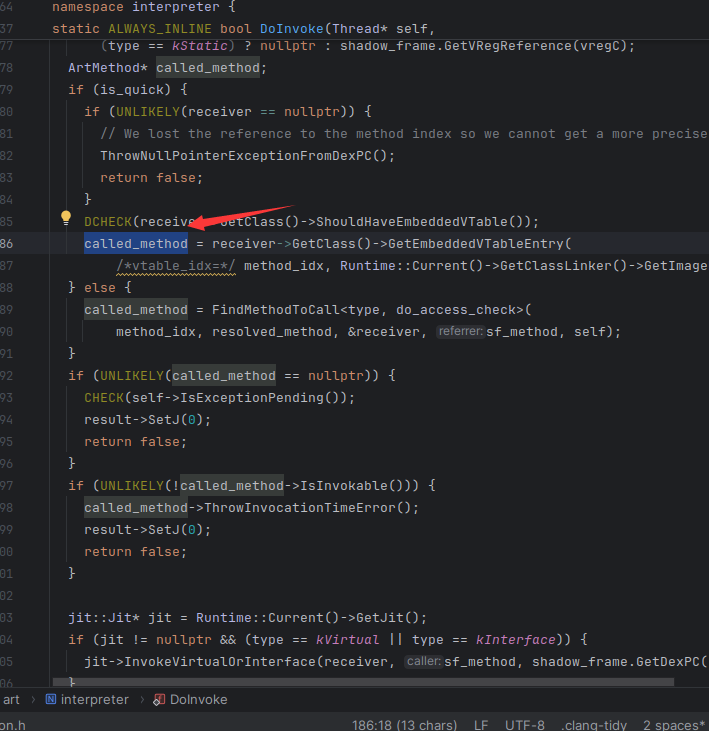
这里跟进去
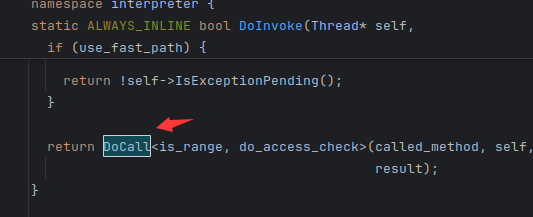
还是没处理函数 继续
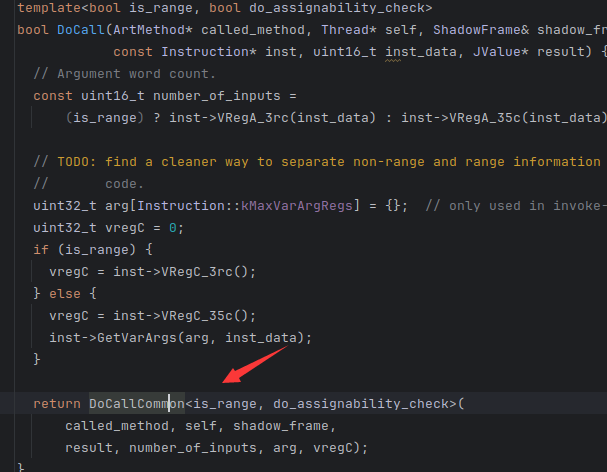
这个就有了 而且new了新函数的栈帧
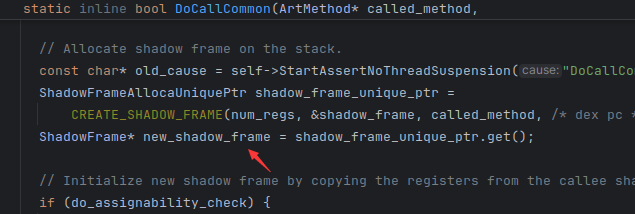
往后调了这个函数
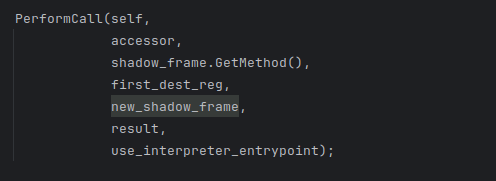
可以看到 调用者 和 被调用的函数的栈帧(函数名直接getmethod),都有了。
而且参数和结果也可以从里面得到,所以我们加代码就可以
可以打印出 java方法调用 一个jni方法或者java方法(其实从native层的调用也可以,不过为了区分,先不写)

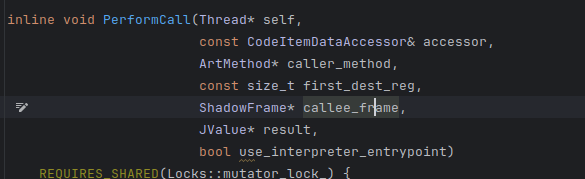
接着往下看 解释模式走这里
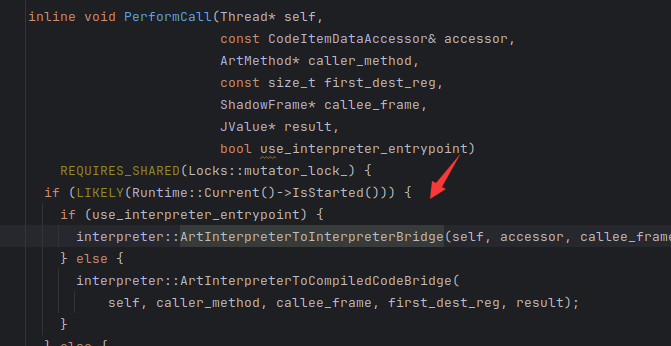
里面又调用了 参数为新函数的execute,开启新一轮invoke
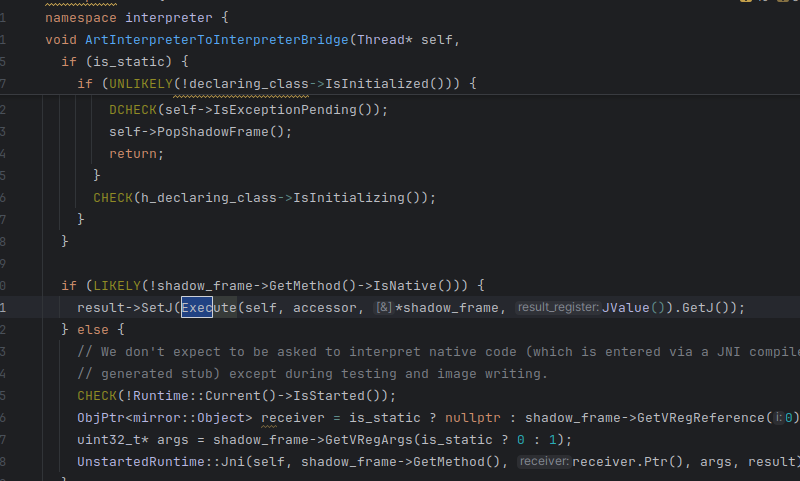
3 jni函数执行流程
为了解决

当然也可以是别种思路
在这里添加代码即可打印 自jni层的函数调用关系
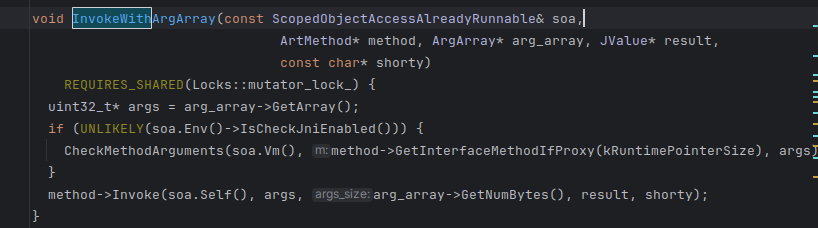
4 强制解释执行
之前的前提都是建立于解释执行之下,它是怎么区分的呢?
[class_linker.cc]linkclass 加载字段,加载方法,然后进行linkcode的操作
linkcode

获取看看有没有quickcode ,然后调用下面的ShouldUseInterpreterEntrypoint判断是否要用解释执行
里面有行这个
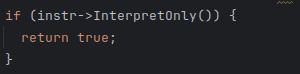
进去
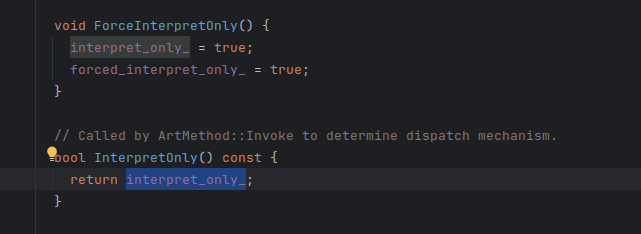
可以看到他只返回一个值,而他的值是上面这个函数设置的。我们要进行强制解释执行就是后面用frida强制调用它。
5 Java调用追踪成品
art/runtime/common_dex_operations.h
里面的performcall函数
// add
ArtMethod* callee = callee_frame->GetMethod();
std::ostringstream oss;
oss << "[PerformCall] " << caller_method->PrettyMethod() << " --> " << callee->PrettyMethod();
if(strstr(oss.str().c_str(),"PerformCallBefore")){
LOG(ERROR) << oss.str();
}
// add
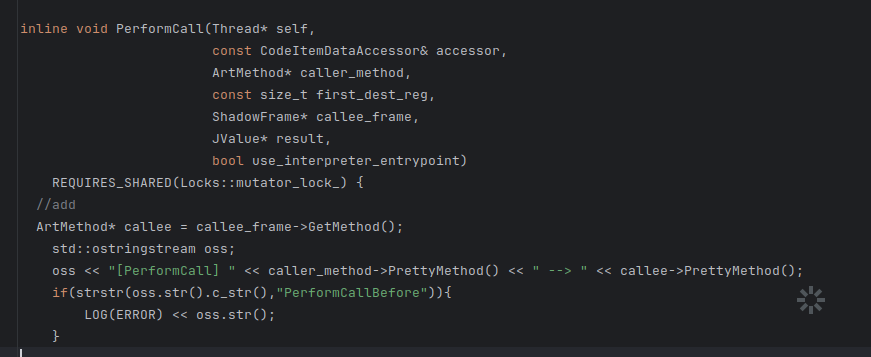
这段代码是肩膀叔的,思路就是同样通过的getmethod获得函数名,然后用PrettyMethod打印出来,把输出流给到oss,然后通过libc里面的strstr,把带有PerformCallBefore输出。然后我们再用frida进行输出的阶段,只要进行PerformCallBefore的过滤吧,就可以得到目前的函数执行流程。
不过我挺疑惑,为啥非要用Frida,很多时候我们改机就是为了隐藏一些痕迹,我觉得尽可能以系统自带手段,像脱壳那种dump,在这里只要加个过滤就可以把所需的信息干净的打印出来,就不需要要Frida了,有时候还需要绕过反Frida,有点麻烦。可能是为了获取尽可能干净的信息?
配合Frida

成功
6 Jni调用追踪成品
原理在第三节
这样改
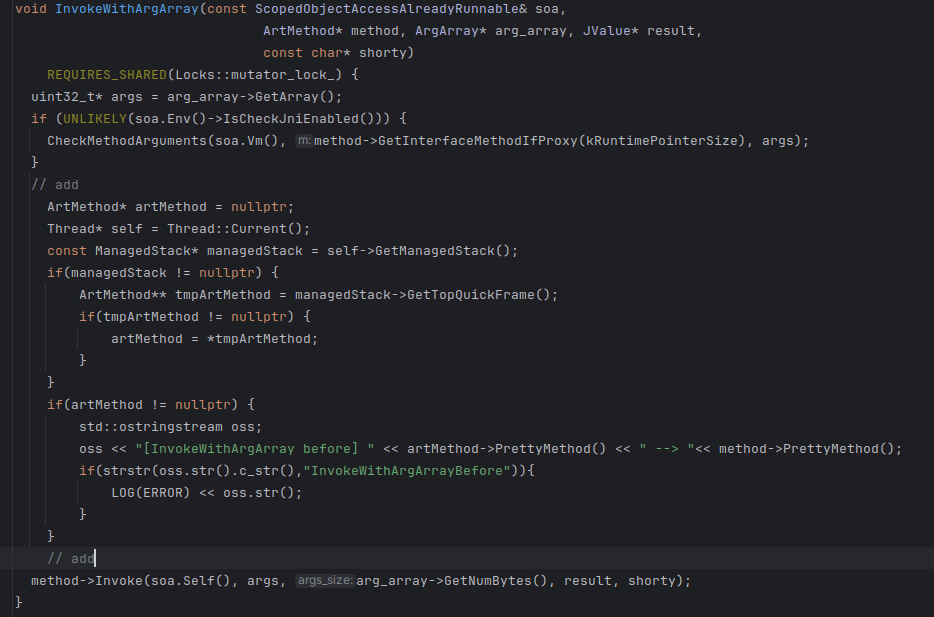
代码
// add
ArtMethod* artMethod = nullptr;
Thread* self = Thread::Current();
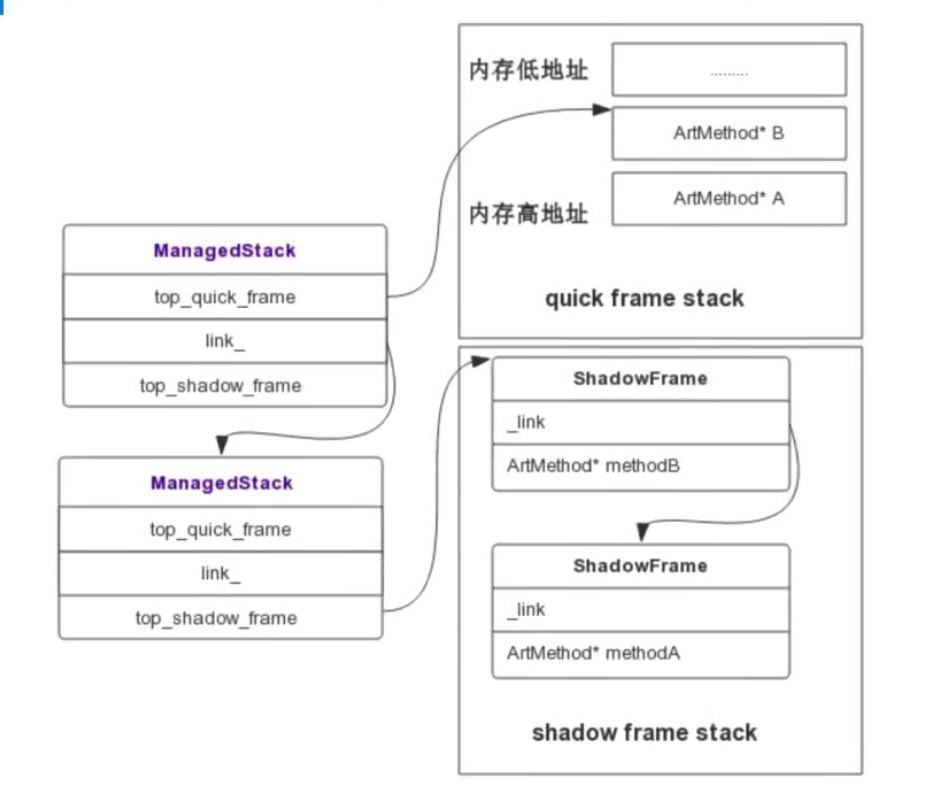
const ManagedStack* managedStack = self->GetManagedStack();
if(managedStack != nullptr) {
ArtMethod** tmpArtMethod = managedStack->GetTopQuickFrame();
if(tmpArtMethod != nullptr) {
artMethod = *tmpArtMethod;
}
}
if(artMethod != nullptr) {
std::ostringstream oss;
oss << "[InvokeWithArgArray before] " << artMethod->PrettyMethod() << " --> "<< method->PrettyMethod();
if(strstr(oss.str().c_str(),"InvokeWithArgArrayBefore")){
LOG(ERROR) << oss.str();
}
}
// add
这段代码 前段代码通过GetManagedStack获得函数栈,然后根据GetTopQuickFrame根据栈顶函数就是调用者(这时还未调用)获得调用者的函数名,通过这种方法进行打印。
其实也可以通过soa.self得到原线程,原线程getpid获得pid。
测试
frida加上这个

有了

7 强制解释执行实现
首先在interpreter.cc里面
硬改
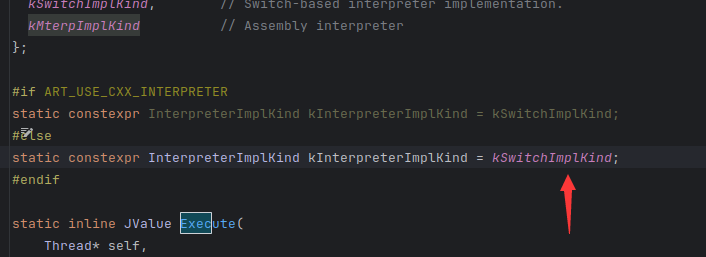
再在文件头的这里添加一个方法
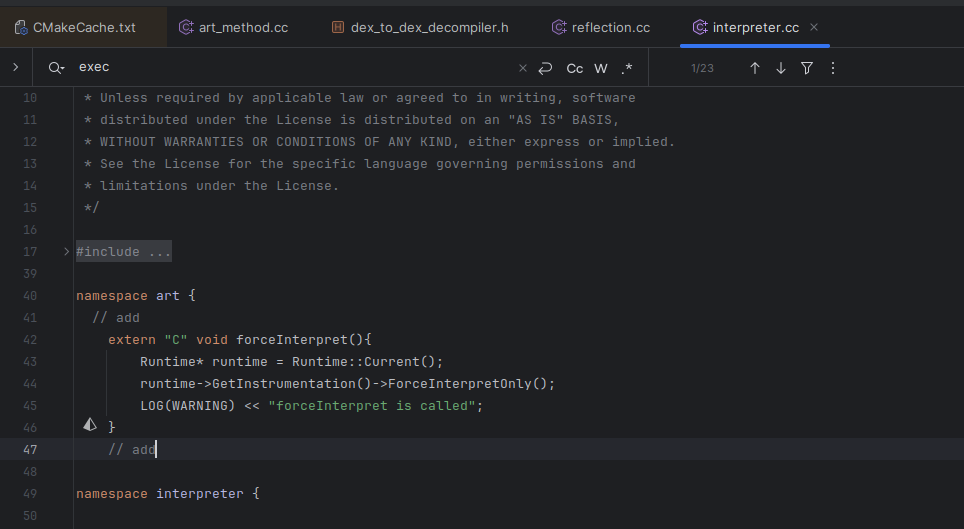
可以看到里面调用了force…的一个函数,之前看过这个函数里两个值被设置为解释器模式
好 编译测试
frida脚本
 确实是走在解释模式下的
确实是走在解释模式下的
注意要用frida启动模式启动app,-f
8 追踪smali原理
之前只有函数调用关系,而没有函数的参数,也不知道函数调用期间的一些局部变量
之前讲过如果解释执行的话 inovke->execute
switch解释器会走到这,还记得吧。
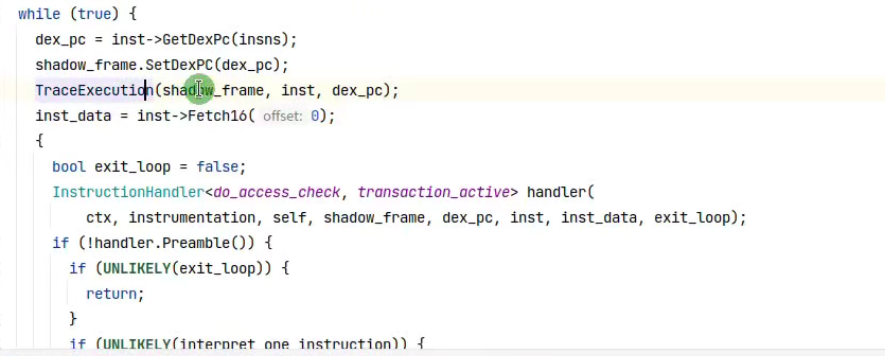
里面会取出opcode转至不同的case
里面的TraceExecution甚至很大程度上对追踪smali有帮助
里面的这三个基本上把想要的都可以打印出来
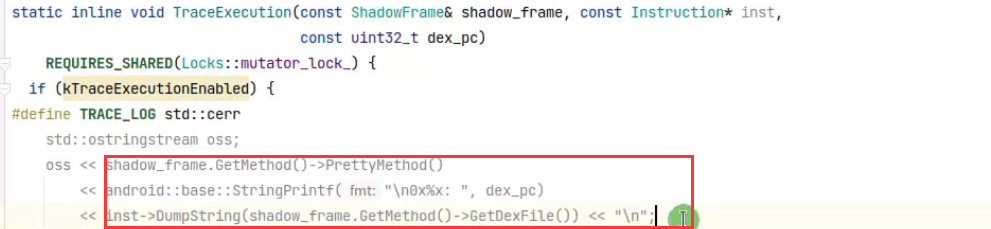
但是这里并没有参数显示,也就是和GDA进行smali反编译的结果一样。
在下面这块 有对寄存器的一些解析和输出
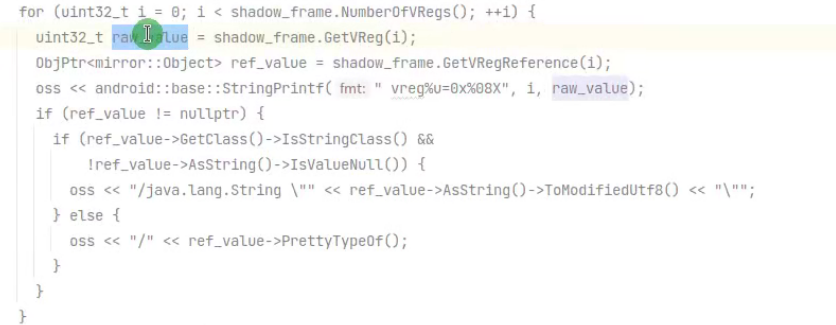
9 追踪smali代码实现及成品
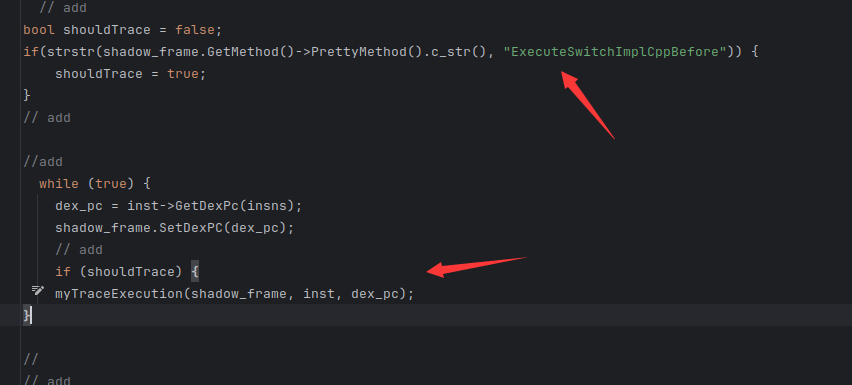
主要是进行两处的魔改
第一处在下图,也就是要用opcode进行case之前添加一段代码,设置一个值,选择是否进行traceexecution,这样的话就不用在每条指令进行case的时候进行判断,也可以指定对什么app进行判断,提高效率(按照正常执行,strstr判断条件不会生效,但是后续可以在frida的onleave面设置返回的值,以此控制是否trace)
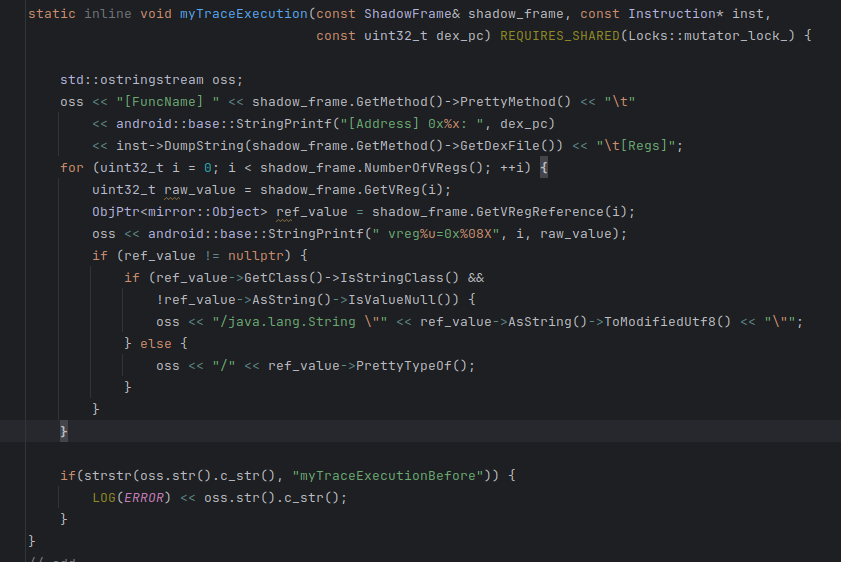
第二处如下,我们在原TraceExecution里面做了一些改动 ,最大的就是结尾的判断条件,也是配合frida作os流过滤的。其他的就是小改动,改了一些输出格式更方便。
ok 编译刷机
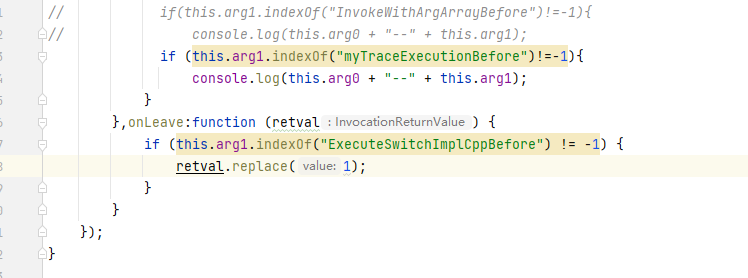
这样 附加hook之后 把东西打印进一个log3.txt

成功如下,我们找到onclick的位置
这一块

拿一个函数看看,比方说getmd5

一个静态方法,参数在v2
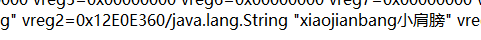
ok了,大功告成。
本篇所有成品全部都在一个编译成品里面。